LLMs struggle to write performant code
If you use AI coding copilots like Cursor or GitHub Copilot, you are unfortunately shipping a lot of slow, un-optimized code. After optimizing 100,000+ open-source functions we found that LLMs struggle with performance. We found that 90% of AI-suggested code optimizations are either incorrect or provide no performance benefits. In this blog, I will show why AI struggles with writing performant code, and show how you can always ship performant code even when using AI coding assistants.
AI's Performance Blind Spot
While AI coding assistants excel at generating functional implementations quickly, they create two distinct performance challenges: they generate code that prioritizes functionality over efficiency, and they struggle with optimizing existing code. Our research at Codeflash reveals that, after optimizing 100K+ open source functions, 90% of optimizations suggested by leading LLMs are incorrect - they either change the code's behavior or fail to improve performance at all. This isn't just our observation; industry data from Harness.io confirms that 52% of engineering leaders report that increased AI usage directly leads to performance problems.

The Complex Art of Performance Optimization
Performance optimization is fundamentally different from simply making code work. It requires deep understanding of algorithmic trade-offs, knowledge of language-specific optimizations, experience with high-performance libraries, and recognition that optimal solutions vary based on data patterns and scale.
When using AI coding assistants, the path of least resistance is implementing the first working solution rather than the most efficient one. High Performance is achieved from understanding both the problem, execution environment and runtime state deeply - a context that LLMs don't have access to.
Where LLMs Fall Short: Optimization Without Verification
.png)
We extensively tested leading LLMs on their ability to optimize real world code. We chose to evaluate LLMs' performance by having them optimize existing code, since this mirrors real-life development where developers first write a working version before attempting to optimize it. Off more than 100K optimizations we attempted, we found disappointing results.
- We found that 62% percent of the suggested optimizations had incorrect behavior. If these were accepted, they would result in bugs, which would often remain hidden.
- Of the optimizations that were found to be correct, 73% resulted in performance gains below 5% or even a decrease in speed - effectively adding complexity without meaningful benefit.
Overall this means that 90% of optimization candidates were just incorrect.
The core issue isn't that LLMs can't suggest alternative implementations; it's that they lack the ability to verify correctness of optimizations and measure actual performance gains through benchmarking. They operate in a theoretical space without execution capabilities.
The Fundamental Limits of AI Code Assistants
The typical AI coding assistant workflow has inherent limitations for performance optimization. First, optimization requires explicit prompting - developers must specifically ask for it, meaning many opportunities are missed. Second, models can't verify the correctness of their suggestions, leading to behavioral changes. Third, models can't benchmark performance against actual workloads to confirm improvements. This forces developers into tedious manual verification processes, negating much of the productivity gain from using AI assistance in the first place.
These aren't temporary limitations that will be solved with larger models or better prompting. They represent fundamental constraints of the copilot-based approach.
Verification: The Missing Piece of the Puzzle
Effective performance optimizations requires an automated verification system working alongside LLM based optimizers. This system must run both original and optimized code against comprehensive test cases, verify identical behavior between implementations, implement proper benchmarking to measure actual performance gains and only select optimizations with significant improvement.
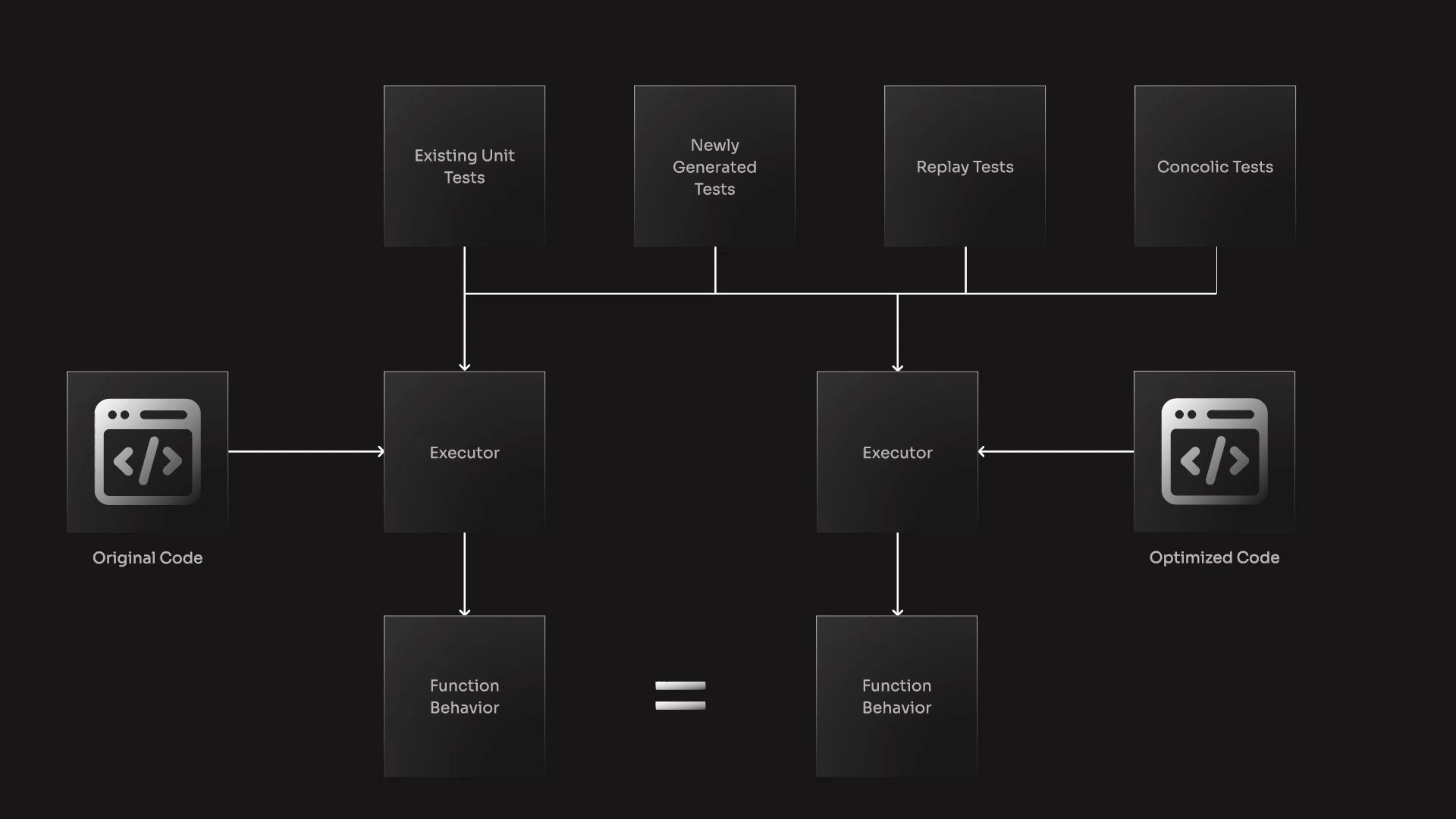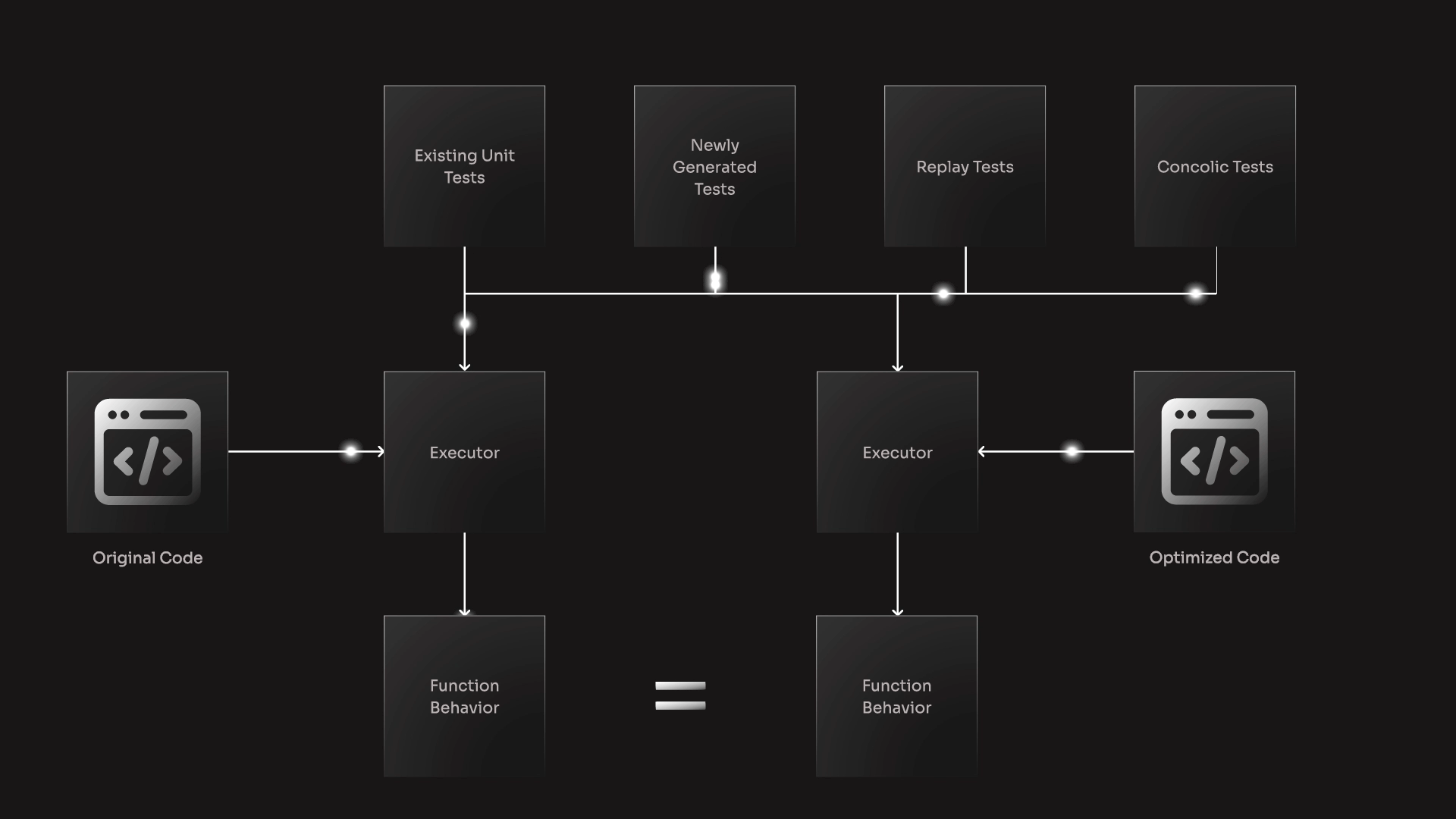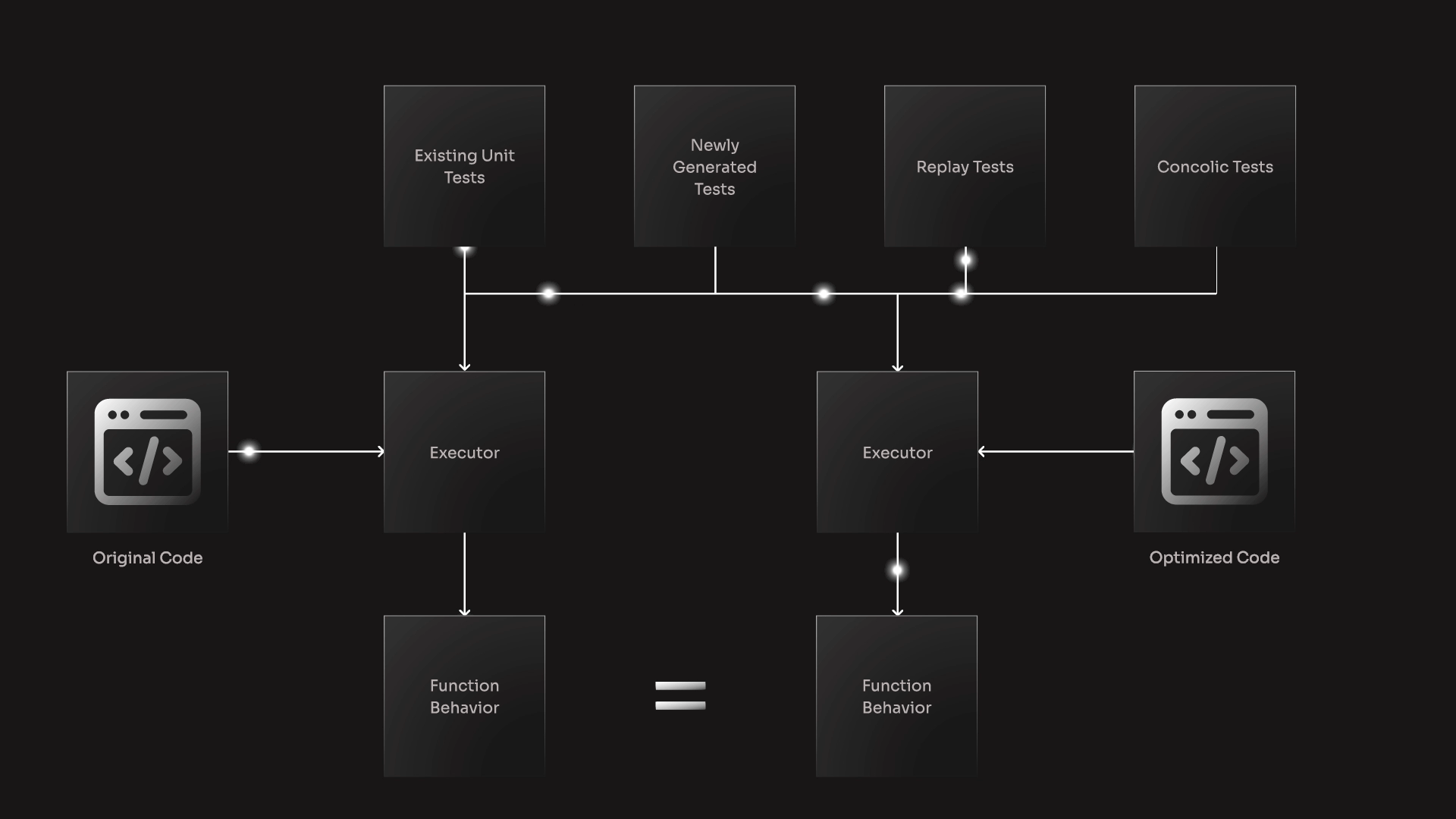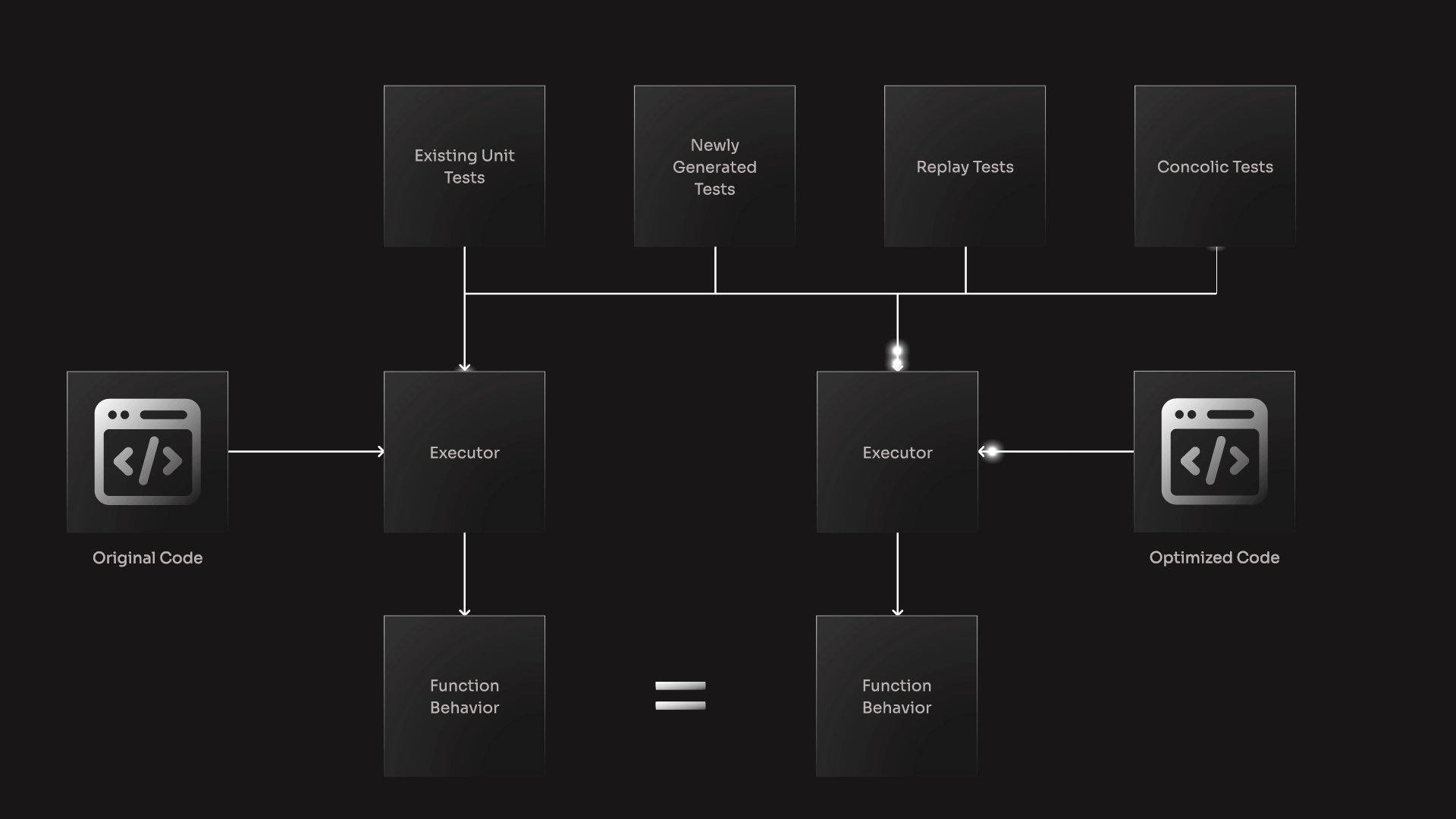
The key insight is that verification, not generation, is the missing piece. By automating the verification process, we maintain all the productivity benefits of AI coding assistants while eliminating their performance blind spots.
Building a Robust Verification System
Codeflash’s approach to this problem combines multiple components. We generate test cases that ensure behavioral correctness across diverse inputs. We analyze the runtime behavior of code through line profiling. We implement state of the art benchmarking techniques that account for system noise and provide confident runtime measurements. We test multiple optimization candidates to find the optimal implementation. And critically, we only present the best verified optimizations to developers, eliminating the guesswork. Codeflash on average discards 15 spurious optimizations before it presents the 1 real optimization.
This isn't about replacing AI coding assistants but complementing them with capabilities they fundamentally lack.
A concrete example
Let's consider an optimization that Codeflash discovered for Albumentations, an image augmentations library. The code applies histogram equalization, converting the image on the left [1] to the image on the right [2]. Histogram equalization enhances an image with low contrast, which spreads out the most frequent intensity values. The equalized image has a roughly linear cumulative distribution function [3]
{{custom-slider}}
Here is the code being optimized. It equalizes an input image stored as a NumPy array, using two Python for loops to perform numerical operations.
1 def _equalize_cv(img: np.ndarray, mask: np.ndarray | None = None) -> np.ndarray:
2 if mask is None:
3 return cv2.equalizeHist(img)
4
5 histogram = cv2.calcHist([img], [0], mask, [256], (0, 256)).ravel()
6 i = 0
7 for val in histogram:
8 if val > 0:
9 break
10 i += 1
11 i = min(i, 255)
12
13 total = np.sum(histogram)
14 if histogram[i] == total:
15 return np.full_like(img, i)
16
17 scale = 255.0 / (total - histogram[i])
18 _sum = 0
19
20 lut = np.zeros(256, dtype=np.uint8)
21
22 for idx in range(i + 1, len(histogram)):
23 _sum += histogram[idx]
24 lut[idx] = clip(round(_sum * scale), np.uint8)
25
26 return sz_lut(img, lut, inplace=True)
The optimization below, found by Codeflash, vectorizes the calculation of the variable i and lut. This runs about 824% faster!
1 def _equalize_cv(img: np.ndarray, mask: np.ndarray | None = None) -> np.ndarray:
2 if mask is None:
3 return cv2.equalizeHist(img)
4
5 histogram = cv2.calcHist([img], [0], mask, [256], (0, 256)).ravel()
6
7 # Find the first non-zero index with a numpy operation
8 i = np.flatnonzero(histogram)[0] if np.any(histogram) else 255
9
10 total = np.sum(histogram)
11 if histogram[i] == total:
12 return np.full_like(img, i)
13
14 scale = 255.0 / (total - histogram[i])
15
16 # Optimize cumulative sum and scale to generate LUT
17 cumsum_histogram = np.cumsum(histogram)
18 lut = np.clip(((cumsum_histogram - cumsum_histogram[i]) * scale).round(), 0, 255).astype(np.uint8)
19
20 return sz_lut(img, lut, inplace=True)
When Codeflash tried another optimization approach shown below, it was correctly flagged as incorrect. The issue occurs at line 8, where using argmax does not identify the first non-zero index.
1 def _equalize_cv(img: np.ndarray, mask: np.ndarray | None = None) -> np.ndarray:
2 if mask is None:
3 return cv2.equalizeHist(img)
4
5 histogram = cv2.calcHist([img], [0], mask, [256], (0, 256)).ravel()
6
7 # Use numpy to find the first non-zero bin.
8 i = np.argmax(histogram > 0)
9
10 total = np.sum(histogram)
11 if histogram[i] == total:
12 return np.full_like(img, i)
13
14 scale = 255.0 / (total - histogram[i])
15 _sum = 0
16
17 lut = np.zeros(256, dtype=np.uint8)
18
19 # Use numpy array operations to fill the lookup table in one step.
20 cumsum = np.cumsum(histogram[i+1:])
21 lut[i+1:] = clip(np.round(cumsum * scale).astype(int)).astype(np.uint8)
22
23 return sz_lut(img, lut, inplace=True)
The bug is subtle and is not easily evident. As you can see, it is hard to verify if an optimization is correct or incorrect when optimizing code manually or reviewing an LLM generated optimization. This requires careful proof-reading and execution of the code on multiple test-cases to ensure correctness. Codeflash's verification system automates this whole process.
From Performance Trade-offs to Performance by Default
The automated optimization approach eliminates the traditional tradeoff during development between performance optimization and shipping velocity tradeoff. Developers don’t have to choose between shipping code quickly, or shipping code that runs fast; they can do both! Technical debt from slow code is fixed before it accumulates. The system works with any coding workflow, whether AI-assisted or not. And perhaps most importantly, developers gain concrete examples of optimized code that improve their performance intuition over time.
Combining Rapid Development with Verified Performance Optimizations
AI coding assistants solve the problem of rapid implementation but introduce performance blindness. Codeflash addresses this challenge by rigorously verifying LLM optimization candidates for both correctness and real performance gains. The future of development combines these approaches: AI for rapid implementation of new features, and tools like Codeflash that convert the AI implementation into its fastest version with strong verified optimizations. Codeflash does not replace coding assistants but it compliments them. Together, they enable both rapid feature implementation and and high performance of those features without compromise.
Want more Codeflash content?
Join our newsletter and stay updated with fresh insights and exclusive content.

Stay in the Loop!
Join our newsletter and stay updated with the latest in performance optimization automation.





{kind=link}
{kind=link}